Extração de Features em Documentos com Azure Cognitive Services
Com a evolução da Inteligência Artificial nos últimos anos, empresas de diversos setores estão procurando aplicar o uso dessa tecnologia a fim de melhorar os seus processos e os tornar mais competitivos, removendo tarefas rotineiras e repetitivas.
Mas recentemente o uso das LLM (Large Language Model — ou Grandes Modelos de Linguagem) conseguiu resolver problemas que até pouco tempo atrás era difícil de ser resolvido. O principal ponto levantado com essa evolução que estamos presenciando é a necessidade dos produtos de software atual incorporarem em seus processos ferramentas ou modelos de AI que simplifiquem a vida de seus usuários removendo tarefas que podem ser facilmente executadas por elas.
Pensando nesse cenário vamos explorar um exemplo prático de como um modelo cognitivo pode apoiar na melhoria da eficiência de um processo operacional em que uma empresa lida com um grande volume de entrada de notas fiscais. Tradicionalmente as entradas desses documentos são feitas via importação de XML, mas existe ainda à necessidade de se fazer o lançamento manualmente em algumas ocasiões. Vamos utilizar aqui a API do Azure Cognitive Service para simular um exemplo de uma possível automatização para a extração de informações desses documentos fiscais, tornando o processo mais eficiente.
Arquitetura
A proposta da arquitetura dessa solução contempla os seguintes aspectos:

- API para operação do processo
- Storage Account para persistência dos dados informados e processados com os resultados extraídos
- Event Grid para automatização do processo de geração de eventos com base no recurso do Storage Account
- Azure Service Bus para propagação do evento gerado pelo Event Grid
- Azure Cognitive Service para processamento e extração de dados do documento enviado
- Event Handler para manipulação do evento publicado e orquestração do processo de extração.
O código do projeto está disponível no github: https://github.com/Angelicogfa/document-feature-extraction
Configuração do Ambiente
Para criar o ambiente vamos utilizar um script do azure cli para a automatizar todo o processo e simplificar nosso trabalho.
az login
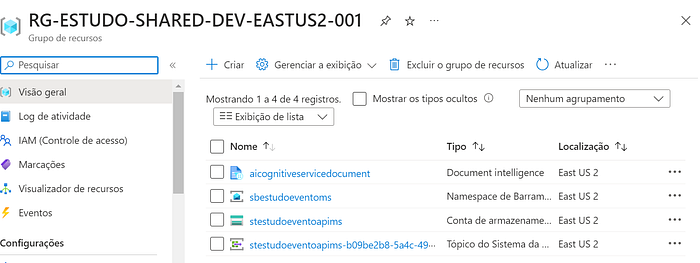
$env:AZURE_RESOURCE_GROUP = "RG-ESTUDO-SHARED-DEV-EASTUS2-001"
$env:AZURE_LOCATION = 'EASTUS2'
$env:AZURE_STORAGE_ACCOUNT = 'stestudoeventoapims'
$env:AZURE_SERVICE_BUS = 'sbestudoeventoms'
$env:AZURE_SERVICE_BUS_QUEUE_NAME = 'estudo.ingestion.document_input_event'
$env:AZURE_SERVICE_DOCUMENT_RECOGNIZER = 'aicognitiveservicedocument'
# Criando o RG
az group create --location ${env:AZURE_LOCATION} --name ${env:AZURE_RESOURCE_GROUP}
# Criando o Storage Account
az storage account create --location ${env:AZURE_LOCATION} --resource-group ${env:AZURE_RESOURCE_GROUP} --name ${env:AZURE_STORAGE_ACCOUNT}
# Obtem a string de conexão com o storage account
az storage account show-connection-string --resource-group ${env:AZURE_RESOURCE_GROUP} --name ${env:AZURE_STORAGE_ACCOUNT} --query connectionString -o tsv
# Obtem o ID do storage account
$env:STORAGE_ACCOUNT_ID=(az storage account show --name ${env:AZURE_STORAGE_ACCOUNT} --resource-group ${env:AZURE_RESOURCE_GROUP} --query id --output tsv)
$env:STORAGE_ACCOUNT_ID
# Criando o service bus
az servicebus namespace create --location ${env:AZURE_LOCATION} --resource-group ${env:AZURE_RESOURCE_GROUP} --name ${env:AZURE_SERVICE_BUS}
# Obtem a string de conexão do azure service bus
az servicebus namespace authorization-rule keys list --resource-group ${env:AZURE_RESOURCE_GROUP} --namespace-name ${env:AZURE_SERVICE_BUS} --name RootManageSharedAccessKey --query primaryConnectionString -o tsv
# Cria uma fila para recebimento dos eventos
az servicebus queue create --resource-group ${env:AZURE_RESOURCE_GROUP} --namespace ${env:AZURE_SERVICE_BUS} --name ${env:AZURE_SERVICE_BUS_QUEUE_NAME}
$env:SERVICE_BUS_QUEUE_ID=(az servicebus queue show --resource-group ${env:AZURE_RESOURCE_GROUP} --namespace ${env:AZURE_SERVICE_BUS} --name ${env:AZURE_SERVICE_BUS_QUEUE_NAME} --query id --output tsv)
$env:SERVICE_BUS_QUEUE_ID
# Criando o provider do event grid
az provider register --namespace Microsoft.EventGrid
# Validando o registro do provider
az provider show -n Microsoft.EventGrid
# Cria um event grid para manipular os eventos de criação de registros em um blob do storage account
az eventgrid event-subscription create `
--name eventgrid-ingestion-input-document `
--source-resource-id ${env:STORAGE_ACCOUNT_ID} `
--endpoint-type servicebusqueue `
--endpoint ${env:SERVICE_BUS_QUEUE_ID} `
--included-event-types Microsoft.Storage.BlobCreated Microsoft.Storage.DirectoryCreated `
--subject-begins-with "/blobServices/default/containers/ingestion/blobs/input/" `
--subject-case-sensitive false
# Cria um serviço do azure cognitive service para reconhecimento e extração de documentos
az cognitiveservices account create `
--name ${env:AZURE_SERVICE_DOCUMENT_RECOGNIZER} `
--resource-group ${env:AZURE_RESOURCE_GROUP} `
--kind FormRecognizer `
--sku S0 `
--location ${env:AZURE_LOCATION} `
--yes
# Obtem o Endpoint
az cognitiveservices account show --name ${env:AZURE_SERVICE_DOCUMENT_RECOGNIZER} --resource-group ${env:AZURE_RESOURCE_GROUP} --query "properties.endpoint" -o tsv
# Obtem a secret
az cognitiveservices account keys list --name ${env:AZURE_SERVICE_DOCUMENT_RECOGNIZER} --resource-group ${env:AZURE_RESOURCE_GROUP} --query "key1" -o tsvO trecho de código acima executa a criação de um grupo de recurso e os respectivos componentes para armazenamento, triggers, publicação de eventos e processamento dos documentos.
Implementando o Código
Criação da API
Vamos criar nossa API utilizando Python com o framework do fastapi para expor nossa aplicação. Essa aplicação irá disponibilizar 4 endpoints:

- POST api/ingestion — Para recebimento do documento a ser processado
- GET api/ingestion/{key}:status — Para retornar o status do processamento
- GET api/ingestion/{key}:files — Para retornar os nomes dos arquivos que foram extraídos
- GET api/ingestion/{key}?file_name — Para retornar o conteúdo do respectivo arquivo
Toda a lógica necessária para execução do processo da aplicação ficará concentrada em uma única classe de serviço responsável por se comunicar com o serviço do storage account.
from io import BytesIO
from config import Config
from azure.storage.blob import BlobServiceClient, BlobClient, ContainerClient
class BlobService:
def __init__(self, config: Config):
self.client = BlobServiceClient.from_connection_string(config.AZURE_BLOB_CONNECTION_STRING)
def save_blob(self, container_name: str, path_file_name: str, file: bytes) -> bool:
container: ContainerClient = self.client.get_container_client(container=container_name)
if not container.exists():
container.create_container()
blob_client: BlobClient = container.get_blob_client(blob=path_file_name)
result = blob_client.upload_blob(file)
return result != None
def check_status(self, container_name: str, folder_name: str) -> bool:
container: ContainerClient = self.client.get_container_client(container=container_name)
if not container.exists():
container.create_container()
blob = container.get_blob_client(folder_name)
if blob is None:
return None
blobs = [blob for blob in container.list_blobs(name_starts_with=folder_name)]
return True if len(blobs) > 1 else False
def get_items(self, container_name: str, folder_name: str) -> list:
container: ContainerClient = self.client.get_container_client(container=container_name)
if not container.exists():
container.create_container()
blobs = [blob.name.split('/')[-1] for blob in container.list_blobs(name_starts_with=folder_name)]
return blobs
def get_item(self, container_name: str, file_name):
container: ContainerClient = self.client.get_container_client(container=container_name)
if not container.exists():
container.create_container()
try:
blob: BlobClient = self.client.get_blob_client('ingestion', blob=file_name)
properties = blob.get_blob_properties()
with BytesIO() as memory_stream:
stream = blob.download_blob()
stream.readinto(memory_stream)
return memory_stream.getvalue(), properties.content_settings.content_type
except:
return NoneCada endpoint por sua vez consumirá o respectivo método do classe de serviço para executar sua operação.
from uuid import uuid4
from config import Config
from fastapi.routing import APIRouter
from fastapi import UploadFile, status
from services.blob_service import BlobService
from fastapi.responses import JSONResponse, Response
router = APIRouter(prefix='/ingestion')
config = Config()
blob_service = BlobService(config)
@router.post('', status_code=status.HTTP_201_CREATED)
async def post(file: UploadFile):
key = str(uuid4())
path_name = f'input/{key}/{file.filename.replace(" ", "")}'
buffer_file = await file.read()
result = blob_service.save_blob('ingestion', path_name, buffer_file)
status_code = status.HTTP_201_CREATED
message = 'Salvo com sucesso'
if not result:
status_code = status.HTTP_400_BAD_REQUEST
message = 'Não foi possível salvar o arquivo'
key = None
return JSONResponse(dict(message=message, key=key), status_code=status_code)
@router.get('/{key}:status', status_code=status.HTTP_200_OK)
async def get_status(key: str):
path_name = f'output/{key}'
result = blob_service.check_status('ingestion', path_name)
if result is None:
return Response(status_code=status.HTTP_404_NOT_FOUND)
elif result is False:
return JSONResponse(dict(message='Em processamento'))
else:
return JSONResponse(dict(message='Processamento finalizado'))
@router.get('/{key}:files', status_code=status.HTTP_200_OK)
def get(key: str):
path_name = f'output/{key}'
blobs = blob_service.get_items('ingestion', path_name)
return JSONResponse(content=blobs)
@router.get('/{key}', status_code=status.HTTP_200_OK)
def get(key: str, file_name: str):
path_name = f'output/{key}/{file_name}'
response = blob_service.get_item('ingestion', path_name)
if response is None:
return Response(status_code=status.HTTP_404_NOT_FOUND)
headers = {'content-type':response[1]}
return Response(content=response[0], headers=headers)Note que toda a operação de persistência ocorrerá dentro de um único container, aqui denominado ingestion. Dentro desse container haverá um diretório de input e outro diretório de output. O input por sua vez manterá apenas o dado que forá recebido no endpoint post. O output, por outro lado, conterá os dados que forem processados e posteriormente disponibilizados.
Criação do serviço de manipulação
O serviço de manipulação do evento, ou event handler, também foi implementado em python e utiliza as próprias bibliotecas do azure para execução dos processos.
Diferente da API, o event handler, possui uma classe de manipulação do evento, o event_handler , e mais dois serviços: o blob_service e o document_service. O blob_service possui praticamente a mesma responsabilidade que o da API, porém com algumas operações a menos, dada sua simplicidade.
from io import BytesIO
from config import Config
from azure.storage.blob import BlobServiceClient, BlobClient, ContainerClient, ContentSettings
class BlobService:
def __init__(self, config: Config):
self.client = BlobServiceClient.from_connection_string(config.AZURE_BLOB_CONNECTION_STRING)
def save_blob(self, container_name: str, path_file_name: str, file: bytes, content_type: str|None = None) -> bool:
container: ContainerClient = self.client.get_container_client(container=container_name)
if not container.exists():
container.create_container()
blob_client: BlobClient = container.get_blob_client(blob=path_file_name)
content: ContentSettings = None
if content_type != None:
content = ContentSettings(content_type=content_type)
result = blob_client.upload_blob(file, content_settings=content)
return result != None
def get_document(self, url: str) -> bytes | None:
blob_name = url.split('ingestion')[1][1:]
with BytesIO() as memory_stream:
blob: BlobClient = self.client.get_blob_client('ingestion', blob=f'{blob_name}')
stream = blob.download_blob()
stream.readinto(memory_stream)
return memory_stream.getvalue()
O document_service por sua vez é responsável pela operação de envio da informação do documento para o serviço do Azure Cognitive Service e recebimento da informação e tratamento dos respectivos dados. Nesse momento fazemos toda a segmentação das possíveis informações extraídas do documento submetido.
from config import Config
from azure.core.credentials import AzureKeyCredential
from azure.ai.formrecognizer import DocumentAnalysisClient
class DocumentService:
def __init__(self, config: Config):
credential = AzureKeyCredential(config.AZURE_DOCUMENT_RECOGNIZER_API_KEY)
self.client = DocumentAnalysisClient(config.AZURE_DOCUMENT_RECOGNIZER_URL, credential)
def analyse_document(self, file: bytes):
poller = self.client.begin_analyze_document('prebuilt-document', document=file)
result = poller.result()
content = result.content
paragrphs = [p.content for p in result.paragraphs]
tables: list[dict] = []
for table in result.tables:
headers = [header for header in table.cells if header.kind == 'columnHeader']
values = [value for value in table.cells if value.kind == 'content']
indices = set([value.row_index for value in values])
rows: list[dict] = []
for indice in indices:
indice_values = list(filter(lambda x: x.row_index == indice, values))
row = dict()
for header in headers:
value = list(filter(lambda x: x.column_index == header.column_index, indice_values))
index_name = 'index' if header.content == '' and indice == 0 else header.content
row[index_name] = None if len(value) == 0 else value[0].content
rows.append(row)
tables.append(dict(row_count=table.row_count, rows=rows))
keyvalue: list[dict] = [{"key": kvp.key.content, "value": kvp.value.content if kvp.value != None else None } for kvp in result.key_value_pairs],
return (content, paragrphs, tables, keyvalue)O event_handler é o orquestrador, ele que recebe o evento do Azure Service Bus e executa a execução de cada serviços.
import json as j
from config import Config
from services.blob_service import BlobService
from services.document_service import DocumentService
class EventHandler:
def __init__(self, config: Config):
self.blob_service = BlobService(config)
self.document_service = DocumentService(config)
def handler_event(self, event: dict) -> bool:
event_data = event['data']
file_url: str = event_data['url']
try:
directory = file_url.split('input')[1].split('/')[1]
buffer = self.blob_service.get_document(file_url)
(content, paragrphs, tables, kv) = self.document_service.analyse_document(buffer)
container = 'ingestion'
directory = f'output/{directory}'
self.blob_service.save_blob(container, f'{directory}/{file_url.split("/")[-1]}', buffer)
if content != None and len(content) > 0:
self.blob_service.save_blob(container, f'{directory}/content.txt', content.encode(), 'application/text')
if paragrphs != None and len(paragrphs) > 0:
self.blob_service.save_blob(container, f'{directory}/paragrphs.json', j.dumps(paragrphs).encode(), 'application/json')
if tables != None and len(tables) > 0:
self.blob_service.save_blob(container, f'{directory}/tables.json', j.dumps(tables).encode(), 'application/json')
if kv != None and len(kv) > 0:
self.blob_service.save_blob(container, f'{directory}/kv.json', j.dumps(kv).encode(), 'application/json')
return True
except:
return FalseExecutando o código
Uma vez que temos nossa arquitetura preparada e aplicação implementada, podemos então executar os projetos. Por se tratarem de aplicações python, podemos então criar os environments e instalar as suas respectivas dependências.
python -m venv .venv
.\.venv\Script\activatepython -m pip install -r .\api\requirements.txt
python -m pip install -r .\handlers\extraction_features\requirements.txtEstando o ambiente preparado precisamos atualizar as variáveis de ambiente de cada projeto, nos seus respectivos arquivos .env (caso não localizem no projeto é porque eles foram ignorados pelo .gitignore, então basta renomear o arquivo .env.dev para .env)
As variáveis de ambiente devem ser preenchidas com base nos valores obtidos no script de criação do ambiente. Lá existem os códigos para extraírem as secrets do service bus, storage account e cognitive services.
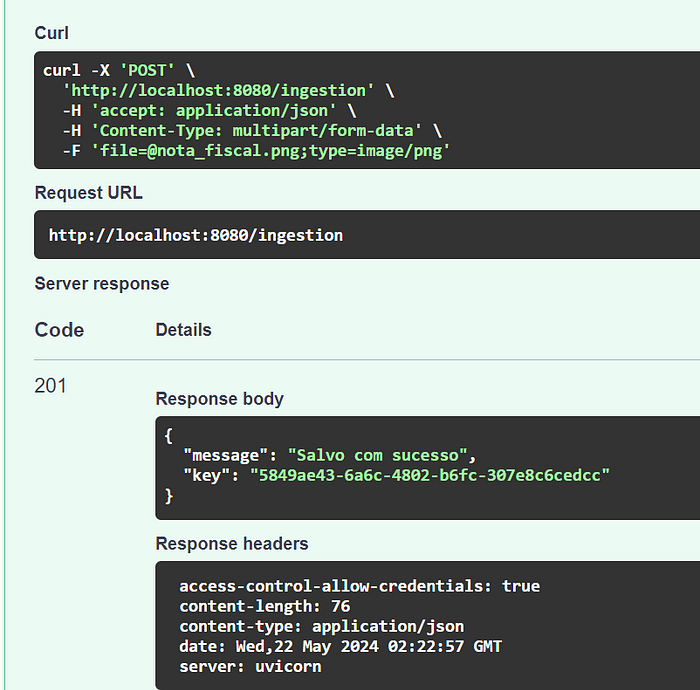
Para esse teste estou submetendo uma imagem de uma nota fiscal. Ao executar o endpoint POST /api/ingestion obtemos o retorno de sucesso.
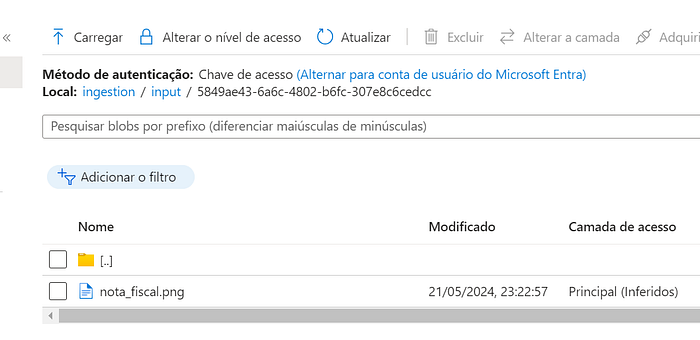
Ao analisar o storage account, podemos observar que fora gerado dentro do container ingestion um diretório input com um subfolder com o mesmo key retornada.
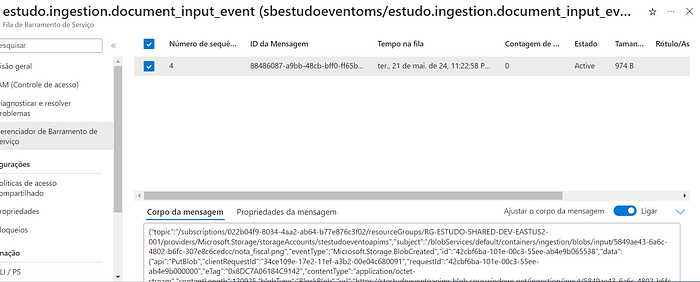
E simultaneamente, um evento fora publicado no service bus (vale ressaltar que se o service do event_handler estiver rodando simultaneamente o serviço consumirá ao mesmo tempo o evento).
Uma vez que o serviço consuma o evento, o documento é encaminhado para o Azure Cognitive Service e os dados extraídos são persistidos no container ingestion no diretório output com um sub-diretório com o mesmo id do diretório de input .
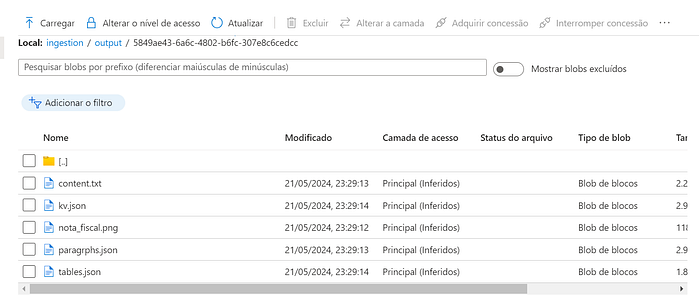
Ao consultarmos na API os próximos endpoint poderemos obter os resultados:
Validação do status
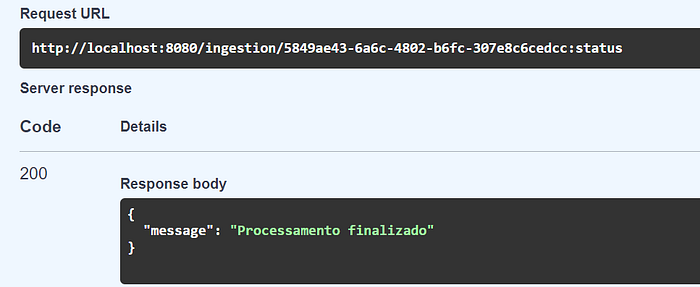
Obtenção das features extraídas
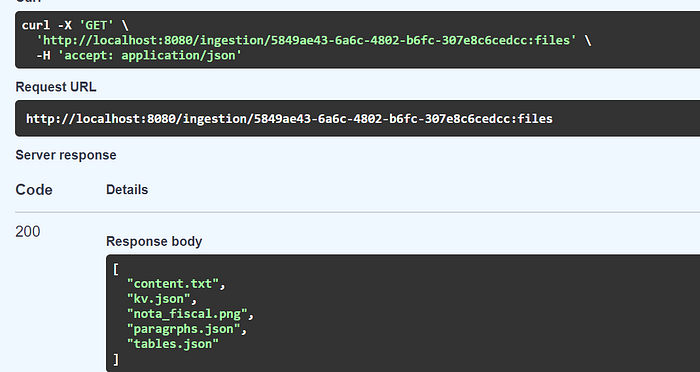
Obtenção dos dados dos arquivos:
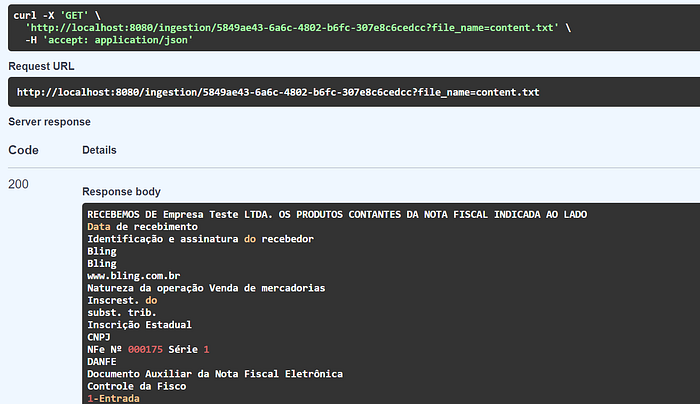
Conclusão
A integração de ferramentas de inteligência artificial nos produtos digitais existentes é uma necessidade crescente para empresas que desejam melhorar a experiência do usuário e otimizar operações internas. O exemplo apresentado demonstra como a automação de processos manuais, como a entrada de dados de notas fiscais, pode trazer eficiência e precisão, beneficiando tanto a empresa quanto seus clientes.
Ao adotar tecnologias avançadas como o Azure Cognitive Services, as empresas não só se mantêm competitivas, mas também se posicionam como inovadoras no mercado, proporcionando valor agregado aos seus usuários e stakeholders.